
Learn to stream big data with Kafka, starting from scratch.
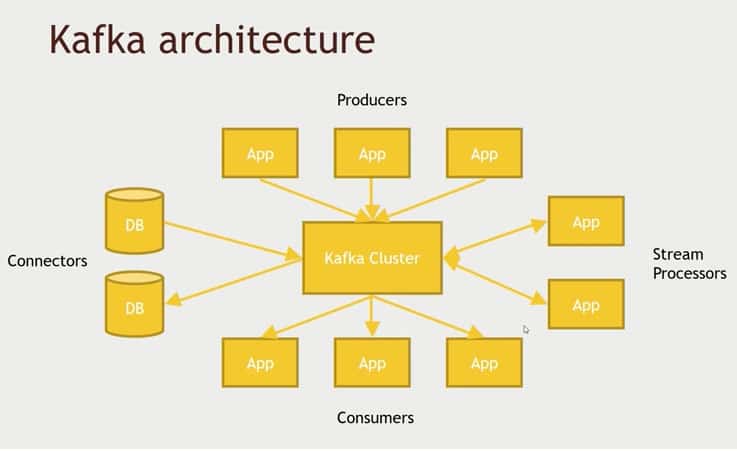
Kafka is a powerful data streaming technology and a very hot technical skill to have right now. With Kafka, you can publish streams of data from web logs, sensors, or whatever else you can imagine to systems that manipulate, analyze, and store that data all in real time. Kafka bring a reliable publish / subscribe mechanism that is resilient and can allow clients to pick up where they left off in the event of an outage.
In this tutorial, you will set up a free Hortonworks sandbox environment within a virtual Linux machine running right on your own desktop PC, learn about how data streaming and Kafka work, set up Kafka, and use it to publish real web logs on a Kafka topic and receive them in real time. Kafka is sometimes billed as a Hadoop killer due to its power, but really it is an integral piece of the larger Hadoop ecosystem that has emerged.
Your instructor is Frank Kane of Sundog Education, bringing nine years of experience as a senior engineer and senior manager at Amazon.com and IMDb.com, where his job involved extracting meaning from their massive data sets, and processing that data in a highly distributed manner.